统计学习方法第三章—k近邻法
统计学习方法第三章—k近邻法
1.k近邻算法
给定训练集,对新的输入实例,在训练集中找到与该实例最邻近的k个实例,把该实例归入到这k个实例的多数属于的类。
2.k近邻模型
2.1 距离度量:实例点间相似程度的反映。
$x_i,x_j$的$L_p$距离:$L_{p}\left(x_{i}, x_{j}\right)=\left(\sum_{i=1}^{n}\left|x_{i}^{(i)}-x_{j}^{(n)}\right|^{p}\right)^{\frac{1}{p}}$
p=2,欧式距离:$L_{2}\left(x_{i}, x_{j}\right)=\left(\sum_{i=1}^{n}\left|x_{i}^{(n)}-x_{j}^{(n)}\right|^{2}\right)^{\frac{1}{2}}$
p=1,曼哈顿距离:$L_{1}\left(x_{i}, x_{j}\right)=\sum_{l=1}^{n}\left|x_{i}^{(l)}-x_{j}^{(l)}\right|$
p=$\infty$,各坐标距离最大值:$L_{\infty}\left(x_{i}, x_{j}\right)=\max {l}\left|x{i}^{(l)}-x_{j}^{(l)}\right|$
2.2 k值的选择
较小k值:近似误差减小,估计误差增大,预测结果对近邻的实例点非常敏感,模型复杂,易过拟合。
较大k值:估计误差减小,近似误差增大,模型简单。
k值一般取比较小的数值,采用交叉验证法选取最优k值。
2.3 分类决策规则
核心思想:多数表决
3.k近邻法实现:kd树
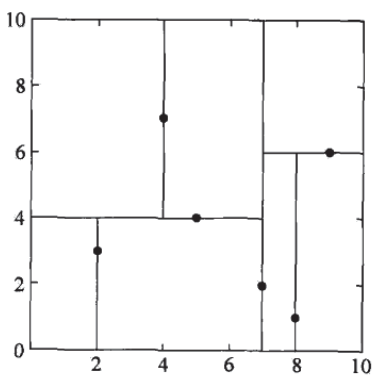
kd树是二叉树,表示对k维空间的一个划分,构造过程相当于不断用垂直于坐标轴的超平面将k维空间切分,构成一系列k维超矩形区域,kd树每个结点对应于一个k维超矩形区域。
例:给定二维空间数据集$T=\left{(2,3)^{\mathrm{T}},(5,4)^{\mathrm{T}},(9,6)^{\mathrm{T}},(4,7)^{\mathrm{T}},(8,1)^{\mathrm{T}},(7,2)^{\mathrm{T}}\right}$,构造一个平衡kd树。